Ranking-Faktor
Als Ranking-Faktor bezeichnet man in der Suchmaschinenoptimierung (SEO) eine Variable, deren Vorhandensein oder Ausprägung auf einer Internet-Seite (oft mutmaßlich) direkten oder indirekten Einfluss auf das durch den Suchmaschinenalgorithmus berechnete Position dieser Seite in den Suchergebnissen hat.
Ranking-Faktoren erklärt: Rang-Korrelationen und ihre kausale Interpretation
Wir bei Searchmetrics veröffentlichen seit 2012 jährlich eine Studie, die unter dem Titel „Ranking-Faktoren“ bekannt ist. Doch was ist eigentlich unsere Definition von „Ranking-Faktor“? Wie genau erfolgt die Analyse? Und was ist eine Korrelation? Da oft Missverständnisse bei der Interpretation unserer Daten als kausale Zusammenhänge aufkommen, soll der Hintergrund und der Interpretationsansatz hier noch einmal erklärt werden.
Merke: Hohe Korrelation bedeutet nicht zwangsläufig Ranking-Faktor!
Die Relevanz einzelner Ranking-Faktoren ist umstritten und zudem von der Interpretation sowie weiteren Faktoren wie Inhaltsart und -zweck abhängig. Da Suchmaschinen wie Google oder Bing ihre zugrundeliegenden Algorithmen nicht veröffentlichen, bleibt deren Evaluation von außen interpretativ, bietet gleichzeitig jedoch Raum für datenbasierte Analysen.
Korrelationen und Rang-Korrelations-Koeffizienten
Jährlich analysieren wir in unserer Ranking-Faktoren-Studie die Top 30 Suchergebnisse für 10.000 Keywords – und damit insgesamt ca. 300.000 URLs. Diese untersuchen wir einzeln auf eine Anzahl von Faktoren, die wir von Jahr zu Jahr erweitern – zum Beispiel die Anzahl von Backlinks, Textlänge sowie Keyword- und Content-Features. Die zugrundeliegende Frage dabei ist stets: Was unterscheidet Seiten, die auf den vorderen Suchergebnispositionen ranken von jenen, die weiter hinten in den SERPs platziert sind? Haben sie vielleicht mehr Backlinks/Text/Keywords/etc.?
Anhand der Existenz bzw. Ausprägung der untersuchten Faktoren über alle 30 Positionen berechnen wir unter Verwendung der Spearman-Korrelation sogenannte Rang-Korrelations-Koeffizienten (hier die Definition von Wikipedia ). Diese geben den Zusammenhang zwischen zwei Variablen wieder – nämlich in diesem Fall dem Ranking auf der einen und der Ausprägung/Existenz des jeweiligen Faktors auf der anderen Seite.
Die Unterschiede über die Suchergebnispositionen hinweg werden dann als Wert zwischen -1 und 1 – sprich: die Korrelation – erfassbar und lassen sich zudem als Kurvenverlauf der Durchschnittswerte pro Position grafisch darstellen.
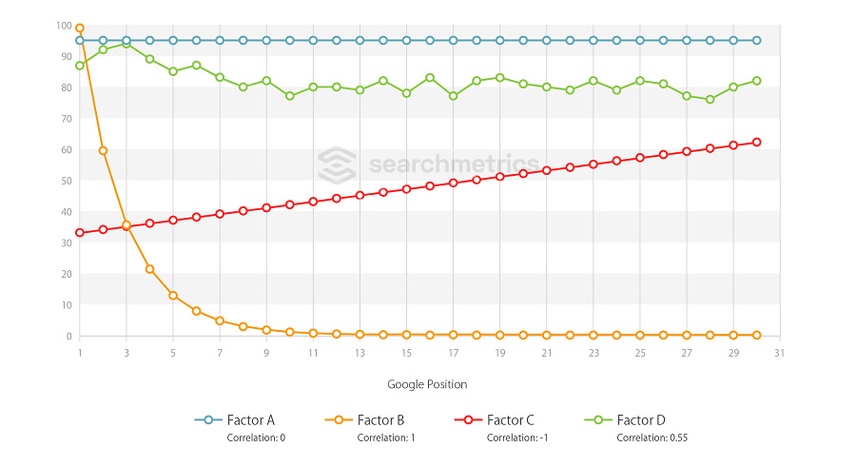
In der Grafik sind vier beispielhafte Korrelationen und Kurvenverläufe dargestellt:
Faktor A: Null Korrelation – lineare Kurve, waagerecht / hoher Durchschnittswert
Faktor B: Positive Korrelation (höchste) – e-Funktion, fallend
Faktor C: Negative Korrelation (niedrigste) – lineare Kurve, steigend
Faktor D: Positive Korrelation – unregelmäßige Kurve, fallend
Zur Erklärung: Korrelations-Berechnung und Interpretationsansätze
Die y-Achse bezeichnet die Durchschnittwerte für alle 10.000 untersuchten URLs auf Position X (x-Achse). Faktoren mit dem Wert „Null“ weisen unseren Auswertungen zufolge keinen messbaren Zusammenhang bezüglich des Unterschieds zwischen besseren und schlechteren Google-Ergebnissen auf. Je höher der Wert einer Korrelation ist, desto größer und regelmäßiger sind die Unterschiede zwischen den Positionen. Werte im Negativbereich sind am besten mit entgegengesetzter Aussage positiv interpretierbar.
Sehr vereinfacht gesagt: Je größer die Unterschiede von Position 1 bis 30 sind, desto höher ist der Korrelationswert. Zur Interpretation der Faktoren sind jedoch immer auch die Durchschnittswerte zu beachten. So sind zum Beispiel die Faktoren B und C vom reinen Korrelationswert (ohne Vorzeichen) her gleich, verlaufen jedoch völlig anders. Bei Faktor A hingegen könnte der Durchschnittwert auch bei 5 verlaufen (y-Achse). Die Korrelation bliebe identisch bei 0, doch die Interpretation wäre eine völlig andere.
Suchmaschinen-Algorithmen und die Ranking-Faktoren von Google & Co.
Suchmaschinen arbeiten mit Algorithmen, um Internetseiten nach Thema und Relevanz zu bewerten. Auf Basis dieser Wertung erfolgt eine Strukturierung der Gesamtheit aller Seiten im Suchmaschinen-Index, welche bei Suchanfragen von Usern schließlich in einer möglichst optimalen Rangfolge der Ergebnisanzeige resultiert. Die Kriterien zur Bewertung von Webseiten und Erzeugung dieser Rangfolge werden im Allgemeinen als Ranking-Faktoren bezeichnet.
Die Gründe dafür liegen auf der Hand: Die exponentiell ansteigende Masse an Dokumenten im Internet – und damit auch im Suchindex – ist trotz der Existenz menschlicher Quality-Rater ohne maschinellen Algorithmus schlicht unmöglich. Dieser Algorithmus ist einerseits trivial (Ordnung erfordert ein Muster), andererseits jedoch zugleich die größte Unbekannte im Internet-Business, denn für Suchmaschinen-Unternehmen ist es unabdingbar, die dem Algorithmus zugrundeliegenden Einflussfaktoren streng vertraulich zu behandeln.
Dies hat weniger Konkurrenzgründe als vielmehr elementare Ursachen: Wären sowohl Definition als auch Einflussgröße von für gute Rankings eminenten Faktoren bekannt, wären sie zugleich wiederum potenziell irrelevant – weil: manipulierbar. Niemand außer Google kennt also die wirklichen „Ranking-Faktoren“. Was wir auf Basis von Rang-Korrelations-Analysen jedoch versuchen ist, aus den Eigenschaften der realen, organischen Suchergebnisse Interpretationen vorzunehmen, was höchstwahrscheinlich Ranking-Faktoren – und zudem deren Gewichtungen untereinander, sein könnten. Unsere immense Datenbank bietet dafür ein verlässliches Fundament.
Black-Hat-SEO: Keyword Stuffing, Cloaking & Co.
Zu Beginn des Suchmaschinen-Zeitalters bewertete beispielsweise Google Seiten für bestimmte Themen als relevant, in denen diesem Thema zugeordnete Suchbegriffe (Keywords ) besonders häufig vorkamen. Seitenbetreibende nutzten dieses Wissen und erzielten mithilfe Keyword-überladener – größtenteils jedoch für den Suchenden irrelevanter – Seiten sehr gute Positionen in den SERPs.
Diese Tatsache erzeugte zunächst nicht nur einen regelrechten Wettbewerb zwischen Suchmaschinen und SEOs, sondern schließlich auch die Geburt des Mythos um die Ranking-Faktoren. Mit dem Ziel der semantischen Suche entstand so ein Geflecht aus Kriterien, die anfänglich streng technisch basiert waren (zum Beispiel: Anzahl von Backlinks ), mittlerweile jedoch auch durch weniger technische Komponenten ergänzt wurden (zum Beispiel: User-Signale).
Diese Tatsache in Verbindung mit dem Streben nach dem optimalen Suchergebnis gipfelte in der ständigen Evolution der Ranking-Faktoren, deren Struktur und Komplexität durch permanent-iterative Update-Zyklen unter dem starken Einfluss von User-Signalen ständigen Optimierungen unterliegt, um für die User individuell stets die relevantesten Suchergebnisse zu erzeugen.
Für Seitenbetreibende bedeutet dies einerseits ein stetig abnehmendes Maß an negativ-manipulativen Einflussoptionen, andererseits jedoch gleichzeitig die Möglichkeit – angesichts der zunehmenden Bekämpfung von Spam, Irrelevanz und Kurzfristigkeit – mithilfe einer nachhaltig ausgerichteten Business-Strategie auf Basis relevanter Qualitätsfaktoren langfristig mit guten Suchergebnis-Positionen erfolgreich zu sein.
Kausalität ≠ Korrelation
Wir sind nicht Google. Die Analyse und Bewertung von Ranking-Faktoren mithilfe unserer Daten hat demzufolge zwar Interpretations-Charakter – stellt jedoch in der Tat eine fundierte Interpretation (und damit keine Mutmaßung) auf Basis von Tatsachen, nämlich der Auswertung und Strukturierung von Eigenschaften von Websites mit Top-Positionen in den Suchergebnissen, dar.
Die Ranking-Auswertungen von Searchmetrics sind exakt und basieren auf sehr vielen Daten. Wir bei Searchmetrics aggregieren monatlich Milliarden von Datenpunkten – und gehen dabei natürlich genau dieser Frage nach: Welche Faktoren unterscheiden gut platzierte Seiten von jenen mit schlechteren Positionen in den Google-Suchergebnissen?
Dazu vergleichen wir die Eigenschaften von Webseiten mit der Summe ihrer Positionen bei Google und leiten daraus eine strukturierte Auflistung von Faktoren ab die stärker oder niedriger gewichtet werden. Sind also in den vorderen Positionen der untersuchten SERPs viele Seiten, die zum Beispiel das Keyword im Title Tag enthalten, dann erkennen wir darin eine hohe Korrelation mit einem guten Ranking. Diese Korrelationen lassen demnach Rückschlüsse darauf zu, welche Merkmale Seiten, die in den Suchergebnissen auf den ersten Plätzen angezeigt werden gemeinsam haben.
Es ist jedoch nachdrücklich darauf hinzuweisen, dass Korrelationen nicht gleichbedeutend sind mit kausalen Zusammenhängen, und folglich keine Garantie besteht, dass die jeweiligen Faktoren tatsächlich einen Einfluss auf das Ranking haben – oder überhaupt von Google als Signal genutzt werden. Was wir bei Searchmetrics jedoch versuchen ist, diese Korrelationen zu interpretieren.
„Cum hoc ergo propter hoc“ – von Fehlschlüssen und Scheinkorrelationen
Pflanzen verdorren, wenn sie kein Wasser bekommen – die Wohnung wird warm, wenn man die Heizung aufdreht – und weil eine Seite viele Social Signals aufweist, rankt sie auf Platz 1? Halt!
Es gibt viele anschauliche Beispiele für sogenannte Scheinkorrelationen oder auch Beurteilungen, die als „Fehlschlüsse“ (Cum hoc ergo propter hoc) bezeichnet werden (zum Beispiel bei Wikipedia ). So etwa die Menge von Störchen und die Geburtenrate in bestimmten Gebieten oder der Zusammenhang zwischen dem Absatz von Speiseeis und dem erhöhten Vorkommen von Sonnenbrand im Sommer. Aber bekommt man wirklich Sonnenbrand vom Eisverzehr? Natürlich nicht. Was in diesen Beispielen vorliegt, ist eine Korrelation, kein kausaler Zusammenhang. (Weitere sehr anschauliche – und lustige – Beispiele hier ).
Der Terminus „Ranking-Faktor“, dessen kausale Bedeutungskomponente aus oben genannten Gründen erfahrungsgemäß zu problematischen Interpretationsansätzen führt, ist in im Zusammenhang unserer Korrelations-Analysen bevorzugt zu verstehen als „Rangkorrelationskoeffizient“. Fehlschlüssen und Scheinkorrelationen möchten wir vorbeugen – und zwar mit einer evaluierten Interpretation und einer guten fundierten Datenbasis.
Datenbasis für die Searchmetrics Ranking-Faktoren
Diese Analyse basiert auf der Grundlage von Suchergebnissen für ein sehr großes Keyword Set von 10.000 Suchbegriffen für Google Deutschland. Ausgangs-Pool sind stets die Top 10.000 Suchbegriffe nach Suchvolumen, aus denen jedoch spezifisch navigationsorientierte Keywords zum Großteil extrahiert werden, um die Auswertungen nicht zu verfälschen. Als navigationsorientierte Keywords werden Suchanfragen aufgefasst, bei denen alle Sucherergebnisse bis auf eines mehr oder weniger irrelevant sind (zum Beispiel: „Facebook Login“).
Datenbasis sind stets die Anzeigen der ersten drei Suchergebnisseiten – organisch. Die Keyword Sets der aufeinanderfolgen Jahre decken sich im Regelfall zu mehr als 90 Prozent mit der Datenbasis der Studie aus dem jeweiligen Vorjahr. Hier haben wir einen Mittelweg gesucht, um zwei Faktoren Rechnung zu tragen, nämlich einerseits den Erhalt des „größten gemeinsamen Nenners“ als optimale Vergleichsbasis zur Vorjahresuntersuchung, und andererseits die Berücksichtigung neuer Keywords, die durch Zuwachs im Suchvolumen in die Top 10.000 aufgestiegen sind.
Die Datenbasis bei Searchmetrics ist stets sehr frisch. Daher werden für aktuelle Untersuchungen auch neue, relevante Keywords herangezogen, wie zum Beispiel „Samsung Galaxy S5 oder „iPhone 6“, die es zu den früheren Untersuchungszeitpunkten noch gar nicht in relevanter Form gab.
Binäre und Numerische Faktoren – Ausprägung versus Existenz
Die untersuchten Faktoren teilen sich in binäre und numerische Features auf. Dies bedeutet, es besteht naturgemäß ein Unterschied in der Art der Faktoren dieser Analyse. Dieser Unterschied sollte bei der Interpretation der Werte nicht vernachlässigt werden.
Elemente, die mithilfe binärer Faktoren beschrieben werden – wie zum Beispiel eine Meta Description auf der Seite – sind entweder vorhanden oder nicht. Es gibt keine Abstufungen. Daneben gibt es Elemente graduellen Charakters, die sich nach je nach Ausprägung unterscheiden. Beispielsweise kann eine URL keinen oder auch sechstausend Backlinks haben – aber auch jeder einzelne natürliche Wert dazwischen ist möglich.
Diese numerischen Faktoren eignen sich in gewisser Hinsicht „besser“ für Untersuchungen unter Verwendung von Korrelationsberechnungen wie jene nach Spearman, da Reihen- und/oder Rangfolgen prinzipiell auf Abstufungen basieren. Auf Spearman-Korrelationen beruhende Aussagen sind rein auf den Korrelationswert bezogen bei numerischen Faktoren also aussagekräftiger.
Um die Aussagekraft der Korrelationen binärer Features in unserer Studie zu stützen, wird deshalb in der Regel zusätzlich ein Durchschnittswert angegeben. Es kann also sein, dass beispielsweise das Feature „Existenz Description“ lediglich mit einem Wert nahe Null mit besseren Rankings korreliert, jedoch effektiv fast 100% aller untersuchten URLs eine Description aufweisen.
Korrelationswerte versus Durchschnittswerte und -kurven
Die grafisch als Balken dargestellten Korrelationswerte werden stets auf Basis aller vorhandenen Daten pro Feature berechnet, also für 10.000 Keywords und je einer Kurve mit 30 Werten pro Keyword.
Bei den Durchschnittswerten und -kurven handelt es sich um eine aus diesen Werten errechnete Mittelwertkurve, die zudem unter Vernachlässigung der Top fünf Prozent je Feature gebildet wurde, um zur Veranschaulichung einen möglichst glatten Kurvenverlauf und eine gemäßigte Skalierung (Y-Achse) zu ermöglichen. Teilweise wären sonst einige Durchschnittswerte nicht zu erkennen. Auch einzelne Mediane und Mittelwerte für Features wurden unter Nichtbeachtung der Top fünf Prozent errechnet.
Der Brand-Faktor
Eine der festen Konstanten in den Studien zu Ranking-Faktoren ist eine auffällige Besonderheit in den Daten geworden, die wir als „Brand-Faktor“ bezeichnen und der sich durch viele Faktoren und Betrachtungen zieht.
Mit Brand-Faktor ist die Feststellung gemeint, dass Webseiten bekannter Marken bzw. mit einer gewissen Autorität und Bekanntheit in der Regel auf den Top-Positionen ranken, auch wenn sie bestimmte Faktoren nicht in dem Maße wie dahinter platzierte URLs erfüllen.
So verfügen Seiten von Brands einerseits im Durchschnitt seltener über eine H1-Überschrift auf der Seite, haben weniger Wörter im Content, aber beispielsweise auch seltener das Keyword in der Description oder dem Meta Title. Kurz: Sie sind aus SEO-Sicht weniger optimiert. Andererseits weisen Markenseiten durchschnittlich deutlich mehr Backlinks und auch Social Signals auf als andere URLs.
Google ist bereits sehr effizient darin, Brands zu bestimmten Bereichen zu identifizieren und deren URLs bevorzugt zu ranken. Werte wie der Wiedererkennungswert, User-Vertrauen und das Image von Marken spiegeln sich also in bestimmter Hinsicht auch in den SERPs wieder.
Intention: Warum Ranking-Faktoren?
Wie der Google-Algorithmus zusammengesetzt ist, weiß wohl mittlerweile nicht mal mehr Google selbst, so komplex sind die Evaluierungsmetriken inzwischen miteinander verwoben. Das Ziel der Searchmetrics „Ranking-Faktoren“-Studien ist demzufolge nicht, eine unanfechtbare „Heilige Schrift“ mit absolutem Wahrheitsanspruch zu sein. Vielmehr stellen alle Searchmetrics-Studien methodische Analysen auf Interpretationsbasis dar, die dazu beitragen sollen, der Online-Branche einen auf umfangreichen Daten basierenden „Werkzeugkasten“ an die Hand zu geben, mithilfe dessen sich – unter Einbeziehung anderer Entscheidungskriterien – fundierte Handlungsentscheidungen ableiten lassen.
Zum 1×1 der Ranking-Faktoren und unseren Studien.
Bereit, das Potenzial deiner Website zu entfalten?


